Multi-armed Bandits[1]
The Easiest model with the Easiest method.
Overview
You are faced repeatedly with a choice among
k different options, or actions. After each choice you receive a numerical reward chosen
from a stationary probability distribution that depends on the action you selected. Your objective is to maximize the expected total reward over some time period.
Policy
Evaluating each action’s expected reward.
Choosing actions randomly.
If $Action_a$ performs better than the others.
Then, choosing actions other than a with a probability of $\epsilon$.
Result
- Action’s Expected Reward Distribution
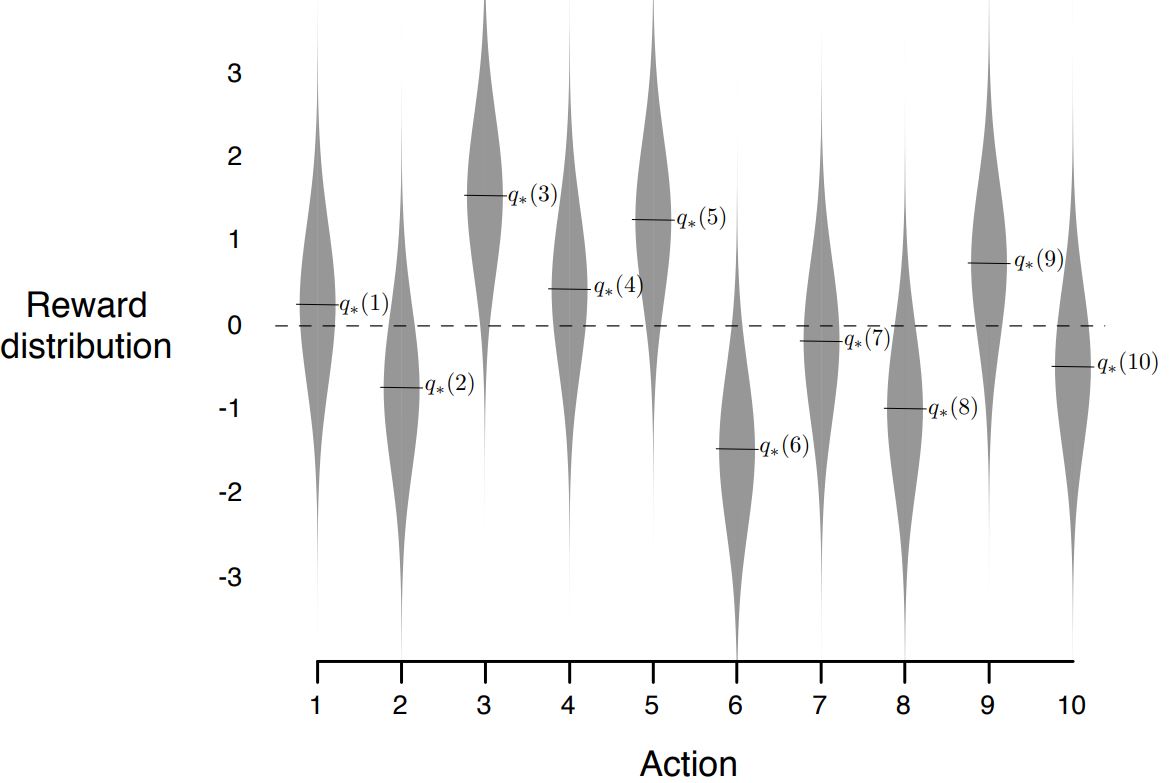
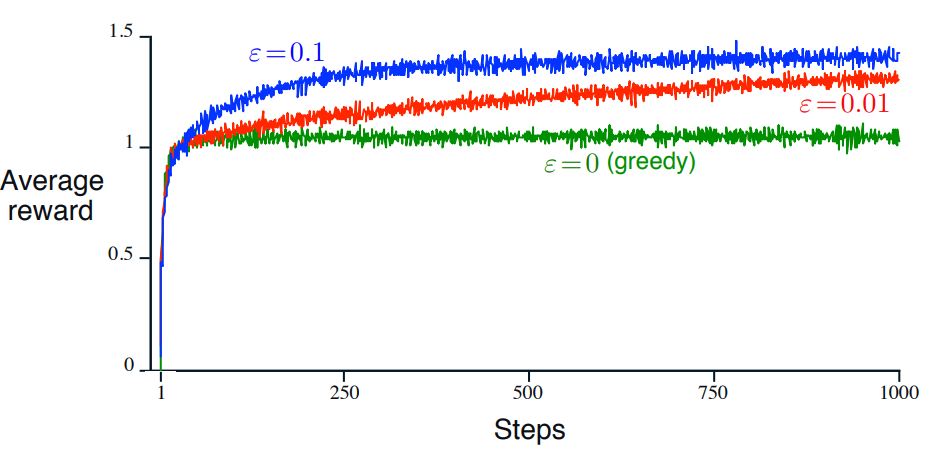
- Actual Performence with different $\epsilon$
Background(Nature)
-
The most important feature distinguishing reinforcement learning from other types of learning is that it uses training information that
evaluatesthe actions taken rather thaninstructsby giving correct actions.[1]Example:
-
So, it’s not hard to understand the whole learning process is
keeping trying.Key Words
- Explore
- Exploit
By the way, when l am writing the passage, a question came into my mind. Why not RL agent keep exploring?
Luckily I gave an explanation myself that the action with higher reward may be more pormising. More importantly, with $\epsilon > 0$ it means keeping trying.
Research Hotspot(Safe RL)
The conclusion is mainly drawn through the survey in 2015[2].(The survey can be pushlished in A-reference.)
Abstract
Safe Reinforcement Learning can be defined as the process of learning policies that maximize the expectation of the return in problems in which it is important to ensure reasonable
system performance and/or respect safety constraints during the learning and/or deployment processes. We categorize and analyze two approaches of Safe Reinforcement Learning.
The first is based on the modification of the optimality criterion, the classic discounted finite/infinite horizon, with a safety factor. The second is based on the modification of the
exploration process through the incorporation of external knowledge or the guidance of a
risk metric.
External knowledge/Guidence
Papers below have been read and summarized by self.
- Expert demonstrations for controlling helicopters.[3]
- Devising a framework for controlling the reward variance(Economy related).[4]
- Student-Teacher Learning via comparing the confidence between them.[5]
- Evolutionary reinforcement learning method.[6]
- Dynamic wave expansion neural network.(All Chinese)[7]
- Hardcore mathematical derivation…[8]
My Opinion
Restriction
- Experiment based on hardware
- Hardcore mathematical derivation
- Cross-domain knowledge(Economy)
Naive Thought
When people learn to dirve cars, they won’t hit the wall anyway.
Reward
One of the basic elements of RL up to human.
- Safety related
- Convenient to improve
- Novel
Proposition: Maybe well-designed reward function can converge more quickly.
Problem
- Theoretically wrong
- Theoretically right with no feasible experiments
- Theoretically right with several experiments supported
- Theoretically right but can’t proof its correct
Plan
- Narrow down the range of papers and continue to read.
- Continue to make experiments based on the open source framework.
- Involved in other research areas.(LOL)
Reference
- 《Reinforcement Learning: An Introduction》. second edition. Richard S. Sutton and Andrew G. Barto
- Garcıa J, Fernández F. A comprehensive survey on safe reinforcement learning[J]. Journal of Machine Learning Research, 2015, 16(1): 1437-1480.
- Tang J, Singh A, Goehausen N, et al. Parameterized maneuver learning for autonomous helicopter flight[C]//2010 IEEE International Conference on Robotics and Automation. IEEE, 2010: 1142-1148.
- Di Castro D, Tamar A, Mannor S. Policy gradients with variance related risk criteria[J]. arXiv preprint arXiv:1206.6404, 2012.
- Torrey L, Taylor M E. Help an agent out: Student/teacher learning in sequential decision tasks[C]//Proceedings of the Adaptive and Learning Agents workshop (at AAMAS-12). 2012.
- de Lope J. Learning autonomous helicopter flight with evolutionary reinforcement learning[C]//International Conference on Computer Aided Systems Theory. Springer, Berlin, Heidelberg, 2009: 75-82.
- Song Y, Li Y, Li C, et al. An efficient initialization approach of Q-learning for mobile robots[J]. International Journal of Control, Automation and Systems, 2012, 10(1): 166-172.
- Tamar A, Xu H, Mannor S. Scaling up robust MDPs by reinforcement learning[J]. arXiv preprint arXiv:1306.6189, 2013.