引言
主要内容来自:https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/download/17376/16225
讲的是如何使用形式化方法(Formal Methods)来确保RL(Reinforcement Learning, 即强化学习)训练时的安全性。
起初看到内容中有很多延伸阅读的论文和一些专业名词,以为是比较艰深的一篇paper,不过静下心来后发现难度尚可。
依旧是按照论文的行文顺序进行一定的解读。
Introduction
在引言部分就有一些值得关注的名词。Cyber-physical systems(简称CPSs),维基译为网络实体系统,详细介绍摘入如下:
实体(Physical):自然界中的或由人类制造的,遵循物理定理在连续的时间内运行的系统。
网络(Cyber):利用计算、通信、及控制系统进行的离散及逻辑化管理。
网络实体系统:(Cyber-Physical System):将实体与网络的各个组成部分在所有层面和维度上紧密结合的系统,对实体及网络进行对称性的深入管理。
CPS实质上是一种多维度的智能技术体系,以大数据、网络与海量计算为依托,通过核心的智能感知、分析、挖掘、评估、预测、优化、协同等技术手段,将计算、通信、控制有机融合与深度协作,做到涉及对象机理、环境、群体的网络空间与实体空间的深度融合。CPS能够从实体空间、环境、活动大数据的采集、存储、建模、分析、挖掘、评估、预测、优化、协同,并与对象的设计、测试和运行性能表征相结合,使网络空间与实体空间深度融合、实时交互、互相耦合、互相更新的网络空间(包括机理空间、环境空间与群体空间的结合);进而,通过自感知、自记忆、自认知、自决策、自重构和智能支持促进工业资产的全面智能化。
最近强化学习开始被应用于关键领域中的CPSs,所以保证其安全性是迫在眉睫的。并且作者认为将经过验证的模型纳入基于强化学习的控制器的安全案例中非常重要,因为对于在开放环境(如自动驾驶汽车)中运行的系统,单独测试是一种难以处理的系统验证和验证方法。
作者提出了Justified Speculative Control(简称为JSC)的安全保障技术,主要内容是将可验证的实时监控与强化学习的训练相结合。详细来说就是当JSC没有检测到模型不准确时,系统的动作被限制为一组经过验证的控制动作。当检测到模型不准确时,系统就可以采取未经验证的、可能不安全的(不准确的)模型操作。
不过,作者也提到JSC也结合了前人的许多方法,比如ModelPlex等。
Background
一般论文的背景阅读可能可有可无,但这篇论文的背景不是我所熟悉的。。。
Differential Dynamic Logic
我译为微分动态逻辑。作者主要通过一个行驶在直线上的汽车的一维模型作为例子给出了简单的混合程序(hybrid program)是如何编写的。
例1描述了一辆汽车,它非确定性地选择以最大加速度a加速或不加速,然后遵循一个微分方程。这个过程可能会重复任意多次(由星号表示)。Because there is no evolution domain constraint on plant, each continuous evolution has any arbitrary non-negative duration r ∈ R。(这句话的细节不是很懂,应该是想表达没有施加多余的约束条件。但ctrl和plant的准确含义我不清楚,看起来ctrl代表控制,而plant意味着需要遵循的微分方程)
Hybrid Program Semantics.
混合程序的一些通用语义。这里我打不出来两个紧连的方括号所以就截图表示,这种状态对在随后会作为定义用来表示定理。表1是正规的一些语法含义。这些都会在建模的时候用到。


Differential Dynamic Logic.
每一个混合程序$\alpha$都和操作符$[\alpha]$和$\langle \alpha \rangle$联系在一起,表达了程序的状态可达性。公式$[\alpha]\phi$表达的是由程序$\alpha$可到达的任何状态,公式$\phi$都是正确的。而$\langle \alpha \rangle \phi$表达的是在程序$\alpha$执行了几次后,公式$\phi$是正确的。然后一般情况下微分动态逻辑的公式形式如下
- $ \theta_{1} \sim \theta_{2}$
- $\neg \phi \mid \phi \land \psi \mid \phi \lor \psi \mid \phi \rightarrow \psi$
- $\forall x \phi \mid \exists x \phi$
- $[\alpha]\phi \mid \langle \alpha \rangle \phi$
其中${\theta}_{i}$是关于实数的数学表达式,$\phi$和$\psi$是公式,$\alpha$是程序,$\sim$意味着大于,小于等关系符号。$s \models P$表达在状态$s$下$P$为真。
这些都是基础的语法,它有助于我们了解之后实际的建模规则。
上述公式表达了如果汽车以非负的速度出发,它仍旧会在一段时间的状态转移后拥有非负的速度的性质。
ModelPlex: Verified Runtime Validation
前人的形式化验证工具。其主要有两个监控器。
Controller Monitors
控制器监视器是布尔函数,用于监视是否违反了混合系统模型的控制器部分。监视器接受两个输入——“pre”状态和“post”状态。当且仅当程序的ctrl片段在“pre”状态下执行时产生“post”状态时,控制器监视器才返回true。例如,模型2的控制监控器为:
其中$a_{post}$是控制器所选择的值。同样$v_{post}\ 和\ p_{post}$也是如此。因此控制器的监控器表明控制器可能会选以加速度a行驶或为0,即匀速行驶,但是可能不会改变$\ p\ $或$\ v$的值。
我们可以将控制器的监控器写成如下的函数:
Model Monitors
ModelPlex也有完整模型的监控器,且只有当系统的控制器选择系统模型所允许的控制动作,并且系统的观测物理与描述系统物理动力学的微分方程相对应时,整个模型监视器才返回true。例如,模型2的完整模型监视器为:
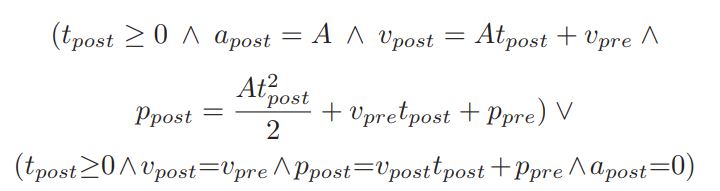
我们可以将监控器写成如下的函数:
其中$S$是状态的集合,$A$是控制器允许的动作。
Reinforcement Learning Models
强化学习的知识在这里就不详细介绍了,有兴趣的同学可以在优酷观看David Silver的课程,我反正第一遍看得是一头雾水。本论文的关键是在安全状态下action的选择,也就是说可能并不会跟随贪婪的想法选出Q(action-value)(s, a)最大的action,而是从指定的集合中选出一个action。在这里作者假定我们使用Q-learning来优化policy。然后如何将上述的形式化验证与强化学习结合在一起呢?可以看如下的截图。也就是说状态和行为的配对满足提前人为设定的动态逻辑程序的规则。

Provably Safe Learning
Generic Justified Speculative Control Algorithm
JSC的主要算法内容如下所示。

伪代码很直白,配以论文的解读比较好理解。就是无论何时,只要整个系统是准确建模的就只采用安全的动作。其中准确建模的意思是完整模型的监控器返回真,采用安全的动作是控制监控器指定使用已知的安全的动作。同时代码假定我们一定有安全的动作可以使用。而其中的update的意思应该就和普通的RL一样,来扩充训练的数据集。
Safety Results
本节给出了这一断言的精确表述,有效地演示了如何将混合系统的形式验证结果转换为增强学习。我们从学习过程的定义开始,学习过程本质上是JSCGeneric算法伪代码的动态系统编码。将该算法重新表述为一个动态系统,使我们能够给出一个精确的参数,而无需为伪代码定义正式的语义。(这段看起来很拗口,确实是简单的文本翻译,导致意思不是很清楚)

序列$u, s, L$分别是JSCGeneric算法每一步所选择的控制动作、状态和学习模型(如Q表或NN)。递归关系等价于在JSCGeneric伪代码中执行的计算,除了上一节讨论的活动警告之外。其中活动警告指的是在此处安全的动作可以是空集。
我们现在准备陈述第一个主要的安全属性——如果环境被准确地建模,JSCGeneric在增强学习过程中不会违反系统的安全特性。
Experimental Validation
实验评估。RL不像DNN那样有诸如MNIST,CIFAR-10等公认的benchmark,所以作者使用了和例子较为相似的一个系统。就是有一辆领航车和一辆跟随车,其中有加速,刹车两种action,而主要的目标是避免两车相撞。经过对比JSC和Normal不同的训练方法,发现JSC在训练10万步后依旧没有出现Crash的情况,而普通的训练出现了近一万次的相撞情况。
Related Work & Conclusions
在相关工作的部分,作者主要想说他们的方法有别于其他前人的方法,要么对优化标准进行限制,要么对其进行修改。而作者的JSC是融入在训练过程里,没有施加多余的操作。
个人总结
- 微分逻辑方程似乎是人为地按照系统的实际意义来设定的
约束。 - 并且看起来是在训练过程中所附加的形式化验证,那如何保证不会在实际应用的过程中出现不安全的
action呢?难道是继续将JSC实施在训练完成的系统中? - 什么叫安全的
action集合?可能也是提前的人为设定,或者说是边学习边填充的呢?个人比较偏向于前者。