引言
论文链接为:https://arxiv.org/abs/1711.00851v3
论文主要提出了一种方法。我们还是从头开始梳理这篇论文吧。
Introduction
作者简单地介绍了近几年的抵御对抗攻击的训练的方法被纷纷打脸。
Somewhat memorably, many of the adversarial defense papers at the most recent ICLR conference were broken prior to the review period completing (Athalye et al., 2018)
这句话的翻译如下:
令人印象深刻的是,最近ICLR会议上的许多对抗防御论文在审查期结束之前就被破坏了。
那么作者就引出了自己的贡献,我也觉得很厉害,所以专门写个Blog详细记录下:
- a method for training
provablyrobust deep ReLU classifiers, classifiers that are guaranteed to be robust againstanynorm-bounded adversarial perturbations on thetraining set. - a provable method for detecting
anypreviously unseen adversarial example, withzero false negatives. 当然作者也说能达到这样的结果也会导致将一些非对抗样本列为对抗样本。
Training Provably Robust Classifiers
-
A $k$ layer feedforward ReLU-based neural network, $f_{\theta}: \mathbb{R} ^ {|x|} \rightarrow \mathbb{R} ^ {|y|} $ given by the equations:
这一段是基本的关于DNN的描述。
-
他们使用集合
来表示对抗多边形(
adversarial polytope)的点的集合,即图1中间那个坐标轴的图形,是非凸的。而他们方法的基础是使用外凸边界(convex outer bound)来包裹对抗多边形。那么只要能保证外凸边界中的点都改变不了最终DNN的输出就能够保证原来的对抗多边形的点也是如此,那么鲁棒性就得到了满足。这是比较好理解的。
-
构造外凸边界的第一步是对于ReLU函数的线性表示。

如图2所示,我们可以用$z \geq 0, z \geq \hat{z}, -u\hat{z} + (u - l)z \leq -ul.$来代替$z = max(0, \hat{z})$。其中如果$l,u$都为正数或负数,那么缩放(
relaxation)是确定的。 -
那么构造外凸边界有什么用呢?作者想找到其中最
坏的点。也就是给定已知$y^{*}$标签的样本$x$,找到$Z_{\epsilon}(x)$其中最小化正确标签输出值且最大化其它标签$y^{tag}$的输出值。这可以通过解决如下的优化问题来解决:其中的$e_{y^{*}}$我觉得可以看成是一个
One-Hot向量。作者说因为目标函数是线性的,故这是一个线性规划问题。所以If we solve this LP for all target classes $y^{tag} \neq y^{*}$ and find that the objective value in all cases is positive (i.e., we cannot make the true class activation lower than the target even in the outer polytope), then we know that no norm-bounded adversarial perturbation of the input could misclassify the example.
作者认为对于测试集也能进行上述的步骤,只是将正确的标签换成了其预测的标签。但这可能会导致非对抗样本被判断成对抗样本,不过这样可以保证所有的对抗样本都被识别了出来。大致的过程讲完以后,作者认为有两个比较严峻的问题:其一是上述的目标线性规划问题通过传统的地方不是很好处理,因为要处理输出层的所有神经元的个数
次;其二是ReLU边界缩放的问题。看到这里我突然发现这好像没谈处理CNN啊。。。
Efficient Optimization via the Dual Network
- 作者认为为了解决第一个问题,我们应该拿出对偶问题。为什么呢?
any feasible dual solution provides a guaranteed lower bound on the solution of the primal.
翻译一下就是任何对偶解法都提供了对原问题有保障的下界。特别重要的是,作者说对偶问题的可行集合可以被表达为一个深度网络,一个和标准BP网络非常像的网络。这就意味着相关的证明可以通过对原网络进行改动后的一次反向传播实现。
作者给出经过对偶转化之后的目标函数和约束,因为式子比较复杂这里我直接贴图。

作者说这就是活生生的反向传播,只不过$\alpha_{i,j}$是自由变量。所以作者表示与其通过$\alpha_{i,j}$来优化目标函数不如直接赋给它一个可行值。比如:
这样做的好处是使得整个反向传播成为了一个线性函数。然后作者又说这样子除了无穷范数的其它扰动都可以通过相应的一些改动来处理,只不过在论文中他们主要关注无穷范数。可能看得懂的小伙伴有些疑问,图里的上下边界($u_{i,j}, l_{i,j}$)是从哪里来的?作者在这里假定我们已经知道了,别急,马上就要介绍方法了。
Computing Activation Bounds
-
作者让我们注意$J_{\epsilon}(x, g_{\theta}(c))$这个对偶函数提供了对于输出层的系数。只不过我们通过确定矩阵$c$计算的是正确的单个输出神经元减去目标神经元的值。那么如果我们令$c = I\ and \ c = -I$,那么是否就获得了输出层系数的上界和下界呢?其中当$c = I$的反向传播如下:

这就催生了计算每一层上下边界的算法。照我的理解,通俗的讲就是将每一层当作输出层,然后分别计算每层ReLU函数的上界和下界范围。最后计算输出层的。可以通过作者给出的算法可见一斑。看到红框里是有双重循环的。 img
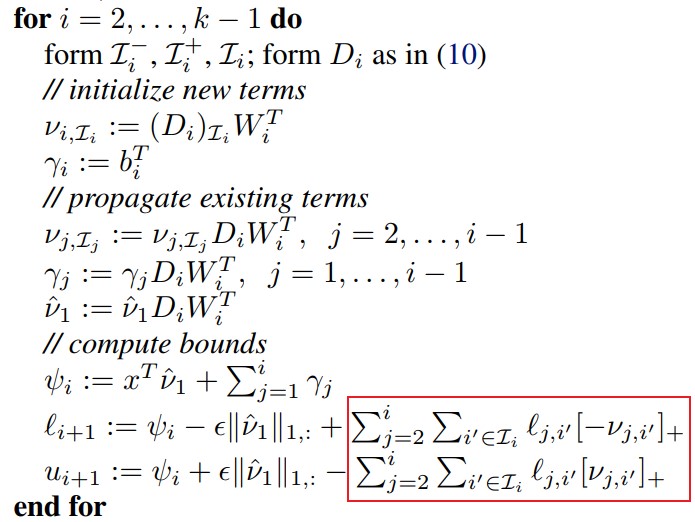{kind=link}
Efficient Robust Optimization
-
接下来就是如何来训练具有鲁棒性的神经网络了。先从目标函数入手。一般的损失函数想要最小化输出向量与正确标签的距离。但为了提高鲁棒性,作者想要最小化在$x_{i}$周围$\epsilon$范围的点最坏的位置的损失函数,也就是: img
作者额外说需要损失函数遵循如下的
性质1:作者说常见的交叉熵,0-1损失都能满足
性质1。按照我的理解并以Softmax为例,应该是说在归一化的时候对所有的输出神经元同时减去一个常数并不会影响最终的损失函数的值。那么为什么需要这个性质呢? img因为作者在输出层减去了单位矩阵,可以看到通过取原函数的上界将问题转换为之前所努力的方向。那么其中复杂的$J$函数是什么意思呢?我在之后的
推论1中了解到了大概。也就是说我们所在目标函数中所求的函数$J$计算的是正确的标签的值减去所有输出层的标签的值,并且根据$J$的定义,是想要它最小,也就是正确的标签的值小于其它标签输出的值。
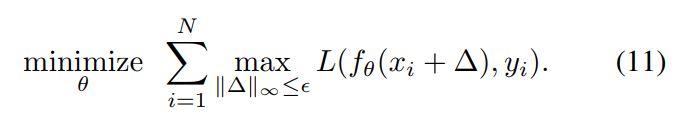{kind=link}
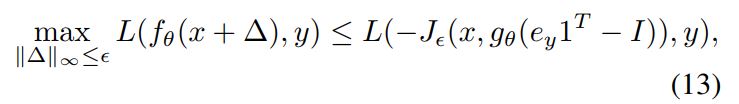{kind=link}
小结
- 写到这终于差不多了,我觉得关键是损失函数的重新建立。按照此损失函数来优化参数不仅提高了准确率也提高了鲁棒性,而且是可验证的鲁棒性。肯定不会遇到作者开头所提到的被攻击者轻易地攻破的情况。但是缺点仔细想想也还是有的,因为你想当我们使用之前简单的损失函数仅提高准确率时还是有些样本无法被准确识别,也就是说,损失函数提供了我们优化参数的方向,但是完全达到100%的准确率,在这是100%的鲁棒性显然是不可能的。同时我觉得这篇论文提供了很新颖的观点,感觉将对抗训练与检测集成在了一起,毕竟检测虽然很重要但不知道如何提高鲁棒性也是很难受的,在这一点上我觉得本论文的想法真的很厉害。接着让我们看看作者的实验和总结。
实验与作者的总结
- 具体的实验数据我这边就不罗列了。主要是在MNIST数据集上达到了5.8%鲁棒性错误率,这是非常可观的。但是作者也提到训练这样的网络所需要的时间是普通训练的两到三个数量级。同时目前的可适应规模也是一个问题。